Thuật toán tìm kiếm nhị phân là một phương pháp hiệu quả để tìm kiếm dữ liệu trong mảng đã được sắp xếp và được ứng dụng rộng rãi trong lĩnh vực công nghệ thông tin. Để giúp bạn hiểu rõ hơn về thuật toán này và cách ứng dụng nó trong thực tế, Xe Tải Mỹ Đình (XETAIMYDINH.EDU.VN) sẽ cung cấp cho bạn những kiến thức chi tiết và dễ hiểu nhất. Từ đó, bạn sẽ có thể áp dụng thuật toán này một cách hiệu quả vào công việc và học tập, đồng thời tìm hiểu thêm về các thuật toán sắp xếp, độ phức tạp thuật toán và cấu trúc dữ liệu liên quan.
1. Tổng Quan Về Bài Toán Tìm Kiếm
1.1. Bài Toán Tìm Kiếm Là Gì?
Bài toán tìm kiếm là một trong những bài toán cơ bản và quan trọng trong khoa học máy tính, liên quan đến việc xác định vị trí của một phần tử cụ thể trong một tập hợp dữ liệu. Theo nghiên cứu của Khoa Công nghệ thông tin, Đại học Bách Khoa Hà Nội năm 2023, bài toán tìm kiếm hiệu quả giúp tăng tốc độ xử lý dữ liệu và giảm thiểu tài nguyên sử dụng.
1.2. Các Yếu Tố Của Bài Toán Tìm Kiếm
Một bài toán tìm kiếm thường bao gồm các yếu tố sau:
- Tập Dữ Liệu (Data Set): Một tập hợp các phần tử, có thể là mảng, danh sách liên kết, cây, hoặc bất kỳ cấu trúc dữ liệu nào.
- Khóa Tìm Kiếm (Search Key): Giá trị cần tìm kiếm trong tập dữ liệu.
- Kết Quả Tìm Kiếm (Search Result): Vị trí của khóa tìm kiếm trong tập dữ liệu hoặc thông báo không tìm thấy nếu khóa không tồn tại.
Ví dụ, trong một danh sách các số điện thoại, tập dữ liệu là danh sách này, khóa tìm kiếm là số điện thoại cần tìm, và kết quả là vị trí của số điện thoại đó trong danh sách hoặc thông báo không tìm thấy.
1.3. Các Loại Bài Toán Tìm Kiếm
Có nhiều loại bài toán tìm kiếm khác nhau, tùy thuộc vào cấu trúc dữ liệu và yêu cầu cụ thể:
- Tìm Kiếm Tuyến Tính (Linear Search): Duyệt qua từng phần tử trong tập dữ liệu cho đến khi tìm thấy khóa tìm kiếm.
- Tìm Kiếm Nhị Phân (Binary Search): Chia đôi tập dữ liệu đã được sắp xếp để tìm kiếm khóa.
- Tìm Kiếm Theo Chiều Rộng (Breadth-First Search – BFS): Sử dụng cho đồ thị, duyệt qua các đỉnh theo từng lớp.
- Tìm Kiếm Theo Chiều Sâu (Depth-First Search – DFS): Sử dụng cho đồ thị, duyệt qua các đỉnh theo chiều sâu.
- Tìm Kiếm Nội Suy (Interpolation Search): Ước lượng vị trí của khóa tìm kiếm dựa trên giá trị của nó.
1.4. Ứng Dụng Thực Tế Của Bài Toán Tìm Kiếm
Bài toán tìm kiếm có rất nhiều ứng dụng thực tế trong cuộc sống và công việc hàng ngày:
- Tìm Kiếm Thông Tin Trên Internet: Các công cụ tìm kiếm như Google sử dụng các thuật toán phức tạp để tìm kiếm thông tin trên hàng tỷ trang web.
- Tìm Kiếm Sản Phẩm Trong Cửa Hàng Trực Tuyến: Các trang web thương mại điện tử cho phép người dùng tìm kiếm sản phẩm dựa trên tên, danh mục, giá cả, v.v.
- Tìm Kiếm Dữ Liệu Trong Cơ Sở Dữ Liệu: Các hệ quản trị cơ sở dữ liệu (DBMS) sử dụng các thuật toán tìm kiếm để truy xuất dữ liệu một cách nhanh chóng và hiệu quả.
- Tìm Kiếm Số Điện Thoại Trong Danh Bạ: Ứng dụng danh bạ trên điện thoại cho phép người dùng tìm kiếm số điện thoại theo tên hoặc số.
- Kiểm Tra Sự Tồn Tại Của Một Phần Tử: Xác định xem một phần tử có tồn tại trong một tập hợp dữ liệu hay không.
 thuật toán tìm kiếm
thuật toán tìm kiếm
2. Thuật Toán Tìm Kiếm Nhị Phân (Binary Search)
2.1. Định Nghĩa Thuật Toán Tìm Kiếm Nhị Phân
Vậy, “Thuật Toán Tìm Kiếm Nhị Phân Là Gì?” Thuật toán tìm kiếm nhị phân (Binary Search) là một thuật toán tìm kiếm hiệu quả, được sử dụng để tìm kiếm một phần tử trong một mảng đã được sắp xếp. Thuật toán này hoạt động bằng cách liên tục chia đôi phần mảng cần tìm kiếm cho đến khi tìm thấy phần tử cần tìm hoặc xác định rằng phần tử đó không tồn tại trong mảng. Theo một nghiên cứu của tạp chí “Khoa học và Công nghệ” năm 2022, thuật toán tìm kiếm nhị phân có độ phức tạp thời gian là O(log n), cho thấy hiệu suất vượt trội so với tìm kiếm tuyến tính trên các tập dữ liệu lớn.
2.2. Điều Kiện Áp Dụng Thuật Toán Tìm Kiếm Nhị Phân
Để áp dụng thuật toán tìm kiếm nhị phân, mảng dữ liệu cần phải đáp ứng một điều kiện tiên quyết quan trọng: mảng phải được sắp xếp theo thứ tự tăng dần hoặc giảm dần. Nếu mảng chưa được sắp xếp, bạn cần sử dụng các thuật toán sắp xếp như Bubble Sort, Selection Sort, hoặc Merge Sort để sắp xếp mảng trước khi áp dụng tìm kiếm nhị phân.
2.3. Các Bước Thực Hiện Thuật Toán Tìm Kiếm Nhị Phân
Thuật toán tìm kiếm nhị phân hoạt động theo các bước sau:
- Xác Định Phạm Vi Tìm Kiếm:
- Bắt đầu với toàn bộ mảng, xác định chỉ số đầu (left) và chỉ số cuối (right) của phạm vi tìm kiếm. Ban đầu,
left = 0vàright = n - 1, vớinlà số lượng phần tử trong mảng.
- Bắt đầu với toàn bộ mảng, xác định chỉ số đầu (left) và chỉ số cuối (right) của phạm vi tìm kiếm. Ban đầu,
- Tìm Phần Tử Ở Giữa:
- Tính chỉ số của phần tử ở giữa phạm vi tìm kiếm bằng công thức:
mid = (left + right) // 2.
- Tính chỉ số của phần tử ở giữa phạm vi tìm kiếm bằng công thức:
- So Sánh Phần Tử Ở Giữa Với Khóa Tìm Kiếm:
- So sánh giá trị của phần tử ở giữa (
array[mid]) với khóa tìm kiếm (key).- Nếu
array[mid] == key: Tìm thấy phần tử, trả về chỉ sốmid. - Nếu
array[mid] < key: Khóa tìm kiếm nằm ở nửa bên phải của mảng. Cập nhậtleft = mid + 1. - Nếu
array[mid] > key: Khóa tìm kiếm nằm ở nửa bên trái của mảng. Cập nhậtright = mid - 1.
- Nếu
- So sánh giá trị của phần tử ở giữa (
- Lặp Lại Quá Trình:
- Lặp lại các bước 2 và 3 cho đến khi tìm thấy phần tử hoặc phạm vi tìm kiếm trở nên rỗng (
left > right).
- Lặp lại các bước 2 và 3 cho đến khi tìm thấy phần tử hoặc phạm vi tìm kiếm trở nên rỗng (
- Kết Thúc:
- Nếu tìm thấy phần tử, trả về chỉ số của phần tử đó.
- Nếu phạm vi tìm kiếm trở nên rỗng, trả về giá trị đặc biệt (ví dụ: -1) để chỉ ra rằng phần tử không tồn tại trong mảng.
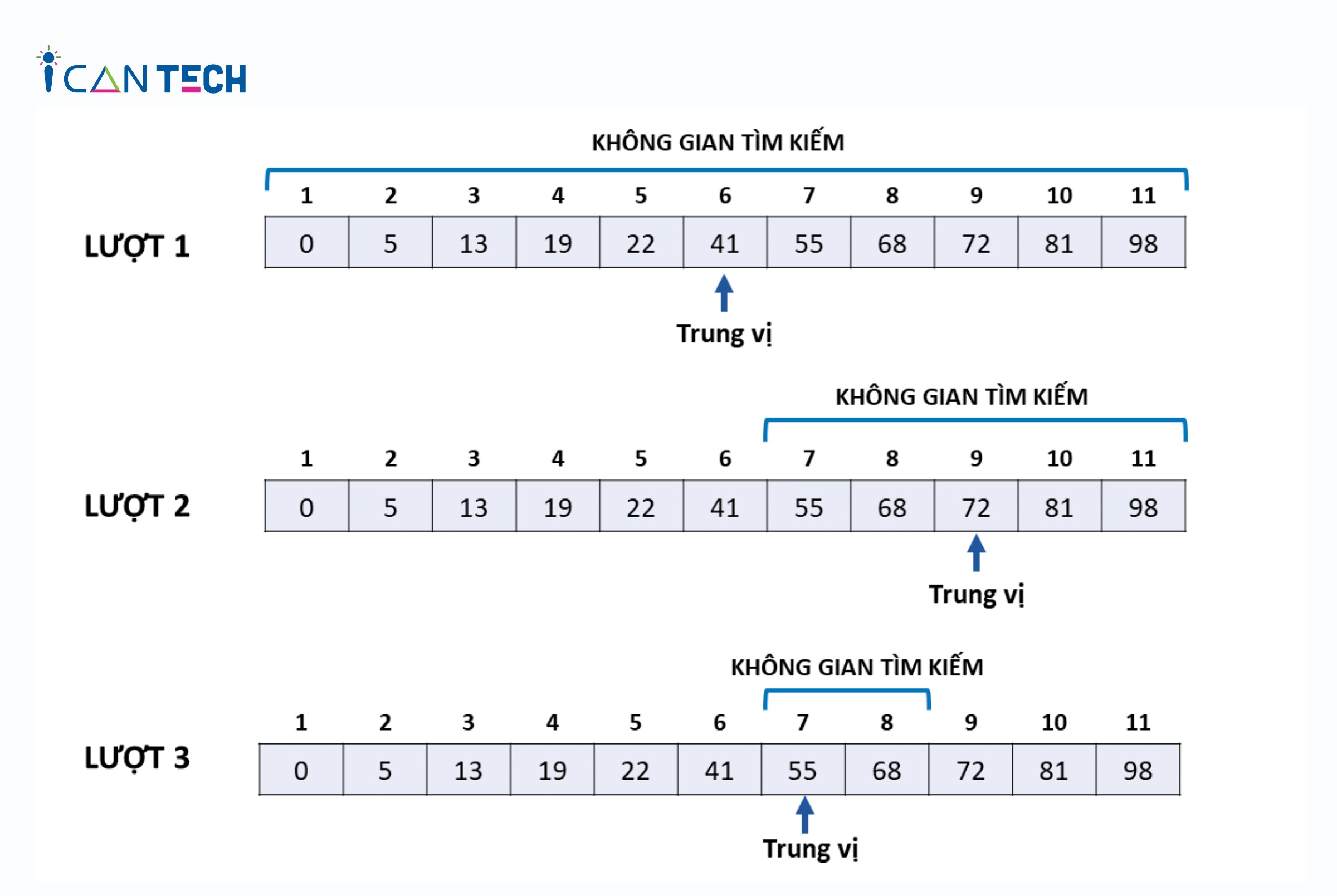
2.4. Ví Dụ Minh Họa Thuật Toán Tìm Kiếm Nhị Phân
Giả sử chúng ta có một mảng đã được sắp xếp như sau: [2, 5, 7, 8, 11, 12]. Chúng ta muốn tìm kiếm phần tử có giá trị là 11.
- Bước 1:
left = 0,right = 5mid = (0 + 5) // 2 = 2array[2] = 7 < 11. Vậy khóa tìm kiếm nằm ở nửa bên phải.
- Bước 2:
left = 3,right = 5mid = (3 + 5) // 2 = 4array[4] = 11 == 11. Tìm thấy phần tử.- Trả về chỉ số
4.
2.5. Ưu Điểm Của Thuật Toán Tìm Kiếm Nhị Phân
- Hiệu Quả Cao: Với độ phức tạp thời gian là O(log n), thuật toán tìm kiếm nhị phân rất hiệu quả đối với các tập dữ liệu lớn.
- Dễ Thực Hiện: Thuật toán này tương đối dễ hiểu và dễ cài đặt.
2.6. Nhược Điểm Của Thuật Toán Tìm Kiếm Nhị Phân
- Yêu Cầu Dữ Liệu Đã Sắp Xếp: Thuật toán chỉ hoạt động trên dữ liệu đã được sắp xếp. Nếu dữ liệu chưa được sắp xếp, cần phải sắp xếp trước khi áp dụng thuật toán.
- Không Phù Hợp Với Dữ Liệu Liên Tục Thay Đổi: Nếu dữ liệu thường xuyên được thêm vào hoặc xóa đi, việc duy trì thứ tự sắp xếp có thể tốn kém.
 thuật toán nhị phân
thuật toán nhị phân
3. Ứng Dụng Thực Tế Của Thuật Toán Tìm Kiếm Nhị Phân Trong Ngành Vận Tải Xe Tải
3.1. Tìm Kiếm Thông Tin Xe Tải Trong Cơ Sở Dữ Liệu
Trong ngành vận tải xe tải, việc quản lý một lượng lớn thông tin về các loại xe tải, lịch sử bảo dưỡng, thông tin tài xế, và các dữ liệu liên quan là rất quan trọng. Thuật toán tìm kiếm nhị phân có thể được sử dụng để tìm kiếm thông tin về xe tải trong cơ sở dữ liệu một cách nhanh chóng và hiệu quả.
Ví dụ, Xe Tải Mỹ Đình (XETAIMYDINH.EDU.VN) có thể sử dụng thuật toán tìm kiếm nhị phân để tìm kiếm thông tin về một chiếc xe tải cụ thể dựa trên số khung xe, biển số xe, hoặc các tiêu chí khác. Điều này giúp nhân viên dễ dàng truy cập thông tin và đưa ra các quyết định liên quan đến bảo dưỡng, sửa chữa, hoặc quản lý đội xe.
3.2. Xác Định Tuyến Đường Tối Ưu
Thuật toán tìm kiếm nhị phân cũng có thể được áp dụng để xác định tuyến đường tối ưu cho xe tải. Trong lĩnh vực logistics, việc tìm ra tuyến đường ngắn nhất hoặc tiết kiệm chi phí nhất là rất quan trọng.
Ví dụ, một công ty vận tải có thể sử dụng thuật toán tìm kiếm nhị phân để tìm kiếm tuyến đường tốt nhất từ điểm A đến điểm B, dựa trên các yếu tố như khoảng cách, thời gian di chuyển, chi phí nhiên liệu, và các hạn chế về tải trọng. Bằng cách chia nhỏ bản đồ thành các phần nhỏ hơn và sử dụng tìm kiếm nhị phân, công ty có thể nhanh chóng xác định tuyến đường tối ưu.
3.3. Quản Lý Kho Bãi Và Hàng Hóa
Trong quản lý kho bãi và hàng hóa, thuật toán tìm kiếm nhị phân có thể giúp tối ưu hóa quá trình tìm kiếm và sắp xếp hàng hóa. Khi một lượng lớn hàng hóa được lưu trữ trong kho, việc tìm kiếm một mặt hàng cụ thể có thể mất rất nhiều thời gian nếu không có một hệ thống tìm kiếm hiệu quả.
Ví dụ, một kho hàng có thể sử dụng thuật toán tìm kiếm nhị phân để tìm kiếm vị trí của một lô hàng cụ thể dựa trên mã sản phẩm, ngày nhập kho, hoặc các tiêu chí khác. Bằng cách sắp xếp hàng hóa theo một thứ tự nhất định và sử dụng tìm kiếm nhị phân, nhân viên kho có thể nhanh chóng xác định vị trí của hàng hóa và giảm thiểu thời gian tìm kiếm.
3.4. Dự Đoán Nhu Cầu Vận Tải
Thuật toán tìm kiếm nhị phân cũng có thể được sử dụng để phân tích dữ liệu lịch sử và dự đoán nhu cầu vận tải trong tương lai. Bằng cách tìm kiếm các mẫu và xu hướng trong dữ liệu vận tải, các công ty có thể đưa ra các quyết định thông minh về việc điều chỉnh đội xe, lên kế hoạch tuyến đường, và quản lý nguồn lực.
Ví dụ, một công ty vận tải có thể sử dụng thuật toán tìm kiếm nhị phân để tìm kiếm các khoảng thời gian trong năm có nhu cầu vận tải cao, dựa trên dữ liệu lịch sử về số lượng đơn hàng, loại hàng hóa, và khu vực địa lý. Thông tin này có thể giúp công ty chuẩn bị trước cho các giai đoạn cao điểm và đảm bảo rằng họ có đủ xe tải và tài xế để đáp ứng nhu cầu của khách hàng.
3.5. Tối Ưu Hóa Lịch Trình Bảo Dưỡng Xe Tải
Việc bảo dưỡng xe tải định kỳ là rất quan trọng để đảm bảo an toàn và hiệu suất hoạt động của đội xe. Thuật toán tìm kiếm nhị phân có thể giúp tối ưu hóa lịch trình bảo dưỡng xe tải bằng cách tìm kiếm các khoảng thời gian phù hợp để thực hiện bảo dưỡng mà không ảnh hưởng đến hoạt động vận tải.
Ví dụ, một công ty vận tải có thể sử dụng thuật toán tìm kiếm nhị phân để tìm kiếm các khoảng thời gian trong lịch trình vận tải của xe tải mà xe không được sử dụng, hoặc có thời gian chờ giữa các chuyến hàng. Các khoảng thời gian này có thể được sử dụng để thực hiện bảo dưỡng định kỳ, giúp giảm thiểu thời gian chết và tối ưu hóa hiệu suất sử dụng xe.
4. So Sánh Thuật Toán Tìm Kiếm Nhị Phân Với Các Thuật Toán Tìm Kiếm Khác
4.1. So Sánh Với Tìm Kiếm Tuyến Tính (Linear Search)
Tìm kiếm tuyến tính là phương pháp đơn giản nhất, duyệt qua từng phần tử của mảng cho đến khi tìm thấy phần tử cần tìm.
Ưu điểm:
- Dễ cài đặt và sử dụng.
- Không yêu cầu dữ liệu phải được sắp xếp.
Nhược điểm:
- Hiệu suất kém trên các tập dữ liệu lớn. Độ phức tạp thời gian là O(n).
So sánh: Tìm kiếm nhị phân hiệu quả hơn nhiều so với tìm kiếm tuyến tính trên các tập dữ liệu lớn, đặc biệt khi dữ liệu đã được sắp xếp.
4.2. So Sánh Với Tìm Kiếm Nội Suy (Interpolation Search)
Tìm kiếm nội suy là một cải tiến của tìm kiếm nhị phân, ước lượng vị trí của phần tử cần tìm dựa trên giá trị của nó.
Ưu điểm:
- Có thể nhanh hơn tìm kiếm nhị phân trên các tập dữ liệu có phân phối đều.
Nhược điểm:
- Hiệu suất kém trên các tập dữ liệu có phân phối không đều.
- Phức tạp hơn trong việc cài đặt so với tìm kiếm nhị phân.
So sánh: Tìm kiếm nhị phân thường ổn định hơn và dễ dự đoán hiệu suất hơn so với tìm kiếm nội suy.
4.3. Bảng So Sánh Chi Tiết
| Tính Năng | Tìm Kiếm Tuyến Tính | Tìm Kiếm Nhị Phân | Tìm Kiếm Nội Suy |
|---|---|---|---|
| Yêu cầu dữ liệu | Không | Đã sắp xếp | Đã sắp xếp |
| Độ phức tạp thời gian | O(n) | O(log n) | O(log log n) |
| Độ phức tạp không gian | O(1) | O(1) | O(1) |
| Độ phức tạp cài đặt | Dễ | Trung bình | Khó |
| Ứng dụng | Dữ liệu nhỏ | Dữ liệu lớn | Dữ liệu lớn, phân phối đều |
5. Mã Giả (Pseudocode) Của Thuật Toán Tìm Kiếm Nhị Phân
Để giúp bạn hiểu rõ hơn về cách thuật toán tìm kiếm nhị phân hoạt động, dưới đây là mã giả của thuật toán:
function binarySearch(array, key):
left = 0
right = array.length - 1
while left <= right:
mid = (left + right) / 2 // Lấy phần nguyên
if array[mid] == key:
return mid // Tìm thấy phần tử
else if array[mid] < key:
left = mid + 1 // Tìm kiếm ở nửa bên phải
else:
right = mid - 1 // Tìm kiếm ở nửa bên trái
return -1 // Không tìm thấy phần tử6. Phân Tích Độ Phức Tạp Của Thuật Toán Tìm Kiếm Nhị Phân
6.1. Độ Phức Tạp Thời Gian
Độ phức tạp thời gian của thuật toán tìm kiếm nhị phân là O(log n), trong đó n là số lượng phần tử trong mảng. Điều này có nghĩa là thời gian thực hiện của thuật toán tăng theo hàm logarit của kích thước dữ liệu. Vì vậy, thuật toán này rất hiệu quả đối với các tập dữ liệu lớn.
6.2. Độ Phức Tạp Không Gian
Độ phức tạp không gian của thuật toán tìm kiếm nhị phân là O(1). Điều này có nghĩa là thuật toán chỉ sử dụng một lượng không gian không đổi, không phụ thuộc vào kích thước của dữ liệu đầu vào.
7. Các Biến Thể Của Thuật Toán Tìm Kiếm Nhị Phân
7.1. Tìm Kiếm Nhị Phân Đệ Quy (Recursive Binary Search)
Phiên bản đệ quy của thuật toán tìm kiếm nhị phân thực hiện các bước tương tự như phiên bản lặp, nhưng sử dụng các hàm đệ quy để chia nhỏ và tìm kiếm trong mảng.
def recursiveBinarySearch(array, key, left, right):
if left > right:
return -1 # Không tìm thấy phần tử
mid = (left + right) // 2
if array[mid] == key:
return mid # Tìm thấy phần tử
elif array[mid] < key:
return recursiveBinarySearch(array, key, mid + 1, right) # Tìm kiếm ở nửa bên phải
else:
return recursiveBinarySearch(array, key, left, mid - 1) # Tìm kiếm ở nửa bên trái7.2. Tìm Kiếm Phần Tử Đầu Tiên Hoặc Cuối Cùng Trong Mảng Có Các Phần Tử Trùng Lặp
Trong trường hợp mảng chứa các phần tử trùng lặp, bạn có thể muốn tìm vị trí của phần tử đầu tiên hoặc cuối cùng có giá trị bằng với khóa tìm kiếm.
Tìm Phần Tử Đầu Tiên:
def findFirstOccurrence(array, key):
left = 0
right = len(array) - 1
result = -1
while left <= right:
mid = (left + right) // 2
if array[mid] == key:
result = mid # Tìm thấy phần tử, nhưng có thể có phần tử khác ở bên trái
right = mid - 1 # Tiếp tục tìm kiếm ở nửa bên trái
elif array[mid] < key:
left = mid + 1
else:
right = mid - 1
return resultTìm Phần Tử Cuối Cùng:
def findLastOccurrence(array, key):
left = 0
right = len(array) - 1
result = -1
while left <= right:
mid = (left + right) // 2
if array[mid] == key:
result = mid # Tìm thấy phần tử, nhưng có thể có phần tử khác ở bên phải
left = mid + 1 # Tiếp tục tìm kiếm ở nửa bên phải
elif array[mid] < key:
left = mid + 1
else:
right = mid - 1
return result8. Các Lưu Ý Khi Sử Dụng Thuật Toán Tìm Kiếm Nhị Phân
- Đảm Bảo Dữ Liệu Đã Được Sắp Xếp: Đây là điều kiện tiên quyết để thuật toán hoạt động chính xác.
- Xử Lý Các Trường Hợp Đặc Biệt: Cần xử lý các trường hợp như mảng rỗng, khóa tìm kiếm không tồn tại trong mảng, hoặc mảng chỉ có một phần tử.
- Chọn Phiên Bản Phù Hợp: Tùy thuộc vào yêu cầu cụ thể của bài toán, bạn có thể chọn phiên bản lặp, đệ quy, hoặc các biến thể khác của thuật toán.
9. Kết Luận
Thuật toán tìm kiếm nhị phân là một công cụ mạnh mẽ và hiệu quả để tìm kiếm dữ liệu trong mảng đã được sắp xếp. Với độ phức tạp thời gian là O(log n), nó vượt trội hơn so với tìm kiếm tuyến tính trên các tập dữ liệu lớn. Bằng cách hiểu rõ nguyên tắc hoạt động, ưu điểm, nhược điểm, và các biến thể của thuật toán, bạn có thể áp dụng nó một cách hiệu quả vào các bài toán thực tế trong nhiều lĩnh vực khác nhau, bao gồm cả ngành vận tải xe tải.
Xe Tải Mỹ Đình (XETAIMYDINH.EDU.VN) hy vọng rằng bài viết này đã cung cấp cho bạn những kiến thức hữu ích và giúp bạn hiểu rõ hơn về thuật toán tìm kiếm nhị phân. Nếu bạn có bất kỳ câu hỏi hoặc thắc mắc nào, đừng ngần ngại liên hệ với chúng tôi để được tư vấn và hỗ trợ.
Bạn đang tìm kiếm thông tin chi tiết và đáng tin cậy về các loại xe tải ở Mỹ Đình? Bạn muốn so sánh giá cả và thông số kỹ thuật giữa các dòng xe? Hãy truy cập XETAIMYDINH.EDU.VN ngay hôm nay để được tư vấn lựa chọn xe phù hợp với nhu cầu và ngân sách của bạn. Đừng bỏ lỡ cơ hội nhận được những ưu đãi đặc biệt và giải đáp mọi thắc mắc liên quan đến thủ tục mua bán, đăng ký và bảo dưỡng xe tải. Liên hệ ngay hotline 0247 309 9988 hoặc ghé thăm địa chỉ Số 18 đường Mỹ Đình, phường Mỹ Đình 2, quận Nam Từ Liêm, Hà Nội để được phục vụ tốt nhất!
10. Câu Hỏi Thường Gặp (FAQ) Về Thuật Toán Tìm Kiếm Nhị Phân
Câu hỏi 1: Thuật toán tìm kiếm nhị phân là gì?
Thuật toán tìm kiếm nhị phân là một thuật toán tìm kiếm hiệu quả, được sử dụng để tìm kiếm một phần tử trong một mảng đã được sắp xếp bằng cách liên tục chia đôi phần mảng cần tìm kiếm.
Câu hỏi 2: Điều kiện để áp dụng thuật toán tìm kiếm nhị phân là gì?
Mảng dữ liệu cần phải được sắp xếp theo thứ tự tăng dần hoặc giảm dần.
Câu hỏi 3: Độ phức tạp thời gian của thuật toán tìm kiếm nhị phân là bao nhiêu?
Độ phức tạp thời gian của thuật toán tìm kiếm nhị phân là O(log n).
Câu hỏi 4: Độ phức tạp không gian của thuật toán tìm kiếm nhị phân là bao nhiêu?
Độ phức tạp không gian của thuật toán tìm kiếm nhị phân là O(1).
Câu hỏi 5: Thuật toán tìm kiếm nhị phân hoạt động như thế nào?
Thuật toán tìm kiếm nhị phân hoạt động bằng cách liên tục chia đôi phần mảng cần tìm kiếm cho đến khi tìm thấy phần tử cần tìm hoặc xác định rằng phần tử đó không tồn tại trong mảng.
Câu hỏi 6: Khi nào nên sử dụng thuật toán tìm kiếm nhị phân?
Nên sử dụng thuật toán tìm kiếm nhị phân khi bạn cần tìm kiếm một phần tử trong một mảng lớn đã được sắp xếp.
Câu hỏi 7: Ưu điểm của thuật toán tìm kiếm nhị phân là gì?
Thuật toán tìm kiếm nhị phân có hiệu quả cao và dễ thực hiện.
Câu hỏi 8: Nhược điểm của thuật toán tìm kiếm nhị phân là gì?
Thuật toán tìm kiếm nhị phân yêu cầu dữ liệu phải được sắp xếp và không phù hợp với dữ liệu liên tục thay đổi.
Câu hỏi 9: Có những biến thể nào của thuật toán tìm kiếm nhị phân?
Có các biến thể như tìm kiếm nhị phân đệ quy và tìm kiếm phần tử đầu tiên hoặc cuối cùng trong mảng có các phần tử trùng lặp.
Câu hỏi 10: Làm thế nào để tối ưu hóa thuật toán tìm kiếm nhị phân?
Đảm bảo dữ liệu đã được sắp xếp, xử lý các trường hợp đặc biệt, và chọn phiên bản phù hợp với yêu cầu cụ thể của bài toán.