Tìm kiếm nhị phân là một thuật toán mạnh mẽ giúp bạn nhanh chóng tìm thấy dữ liệu trong danh sách đã được sắp xếp. Tại XETAIMYDINH.EDU.VN, chúng tôi cung cấp thông tin chi tiết và dễ hiểu về thuật toán này, giúp bạn áp dụng nó hiệu quả vào công việc. Thuật toán này, còn được gọi là tìm kiếm nửa khoảng, là một kỹ thuật quan trọng trong khoa học máy tính, đặc biệt hữu ích khi làm việc với lượng lớn dữ liệu. Hãy cùng Xe Tải Mỹ Đình khám phá sâu hơn về thuật toán này, từ định nghĩa cơ bản đến các ứng dụng thực tế và biến thể nâng cao, giúp bạn làm chủ kỹ năng tìm kiếm dữ liệu hiệu quả.
1. Tìm Kiếm Nhị Phân: Khái Niệm Cơ Bản
Tìm kiếm nhị phân là một thuật toán tìm kiếm hiệu quả, được sử dụng để tìm một phần tử cụ thể trong một danh sách đã được sắp xếp (ví dụ: mảng số, danh sách tên). Thay vì kiểm tra từng phần tử một cách tuần tự như tìm kiếm tuyến tính, tìm kiếm nhị phân liên tục chia đôi phần danh sách mà phần tử cần tìm có thể nằm trong đó, cho đến khi tìm thấy phần tử hoặc xác định rằng nó không có trong danh sách. Điều này giúp giảm đáng kể thời gian tìm kiếm, đặc biệt là với các danh sách lớn.
Tìm kiếm nhị phân hoạt động như thế nào?
- Bắt đầu với toàn bộ danh sách: Xác định điểm đầu (L) và điểm cuối (R) của danh sách.
- Tìm điểm giữa: Tính chỉ số của phần tử nằm giữa danh sách: M = (L + R) / 2.
- So sánh:
- Nếu phần tử ở giữa (A[M]) bằng với giá trị cần tìm (X), thuật toán kết thúc và trả về chỉ số M.
- Nếu A[M] lớn hơn X, điều này có nghĩa là X (nếu có) phải nằm ở nửa đầu của danh sách. Do đó, cập nhật điểm cuối R = M – 1 và quay lại bước 2.
- Nếu A[M] nhỏ hơn X, điều này có nghĩa là X (nếu có) phải nằm ở nửa sau của danh sách. Do đó, cập nhật điểm đầu L = M + 1 và quay lại bước 2.
- Kết thúc: Nếu L > R, điều này có nghĩa là giá trị X không có trong danh sách.
1.1 Ưu điểm vượt trội của thuật toán tìm kiếm nhị phân
Thuật Toán Tìm Kiếm Nhị Phân mang lại nhiều ưu điểm so với các phương pháp tìm kiếm khác, đặc biệt là khi làm việc với dữ liệu lớn. Theo một nghiên cứu của Đại học Bách Khoa Hà Nội năm 2023, tìm kiếm nhị phân có độ phức tạp thời gian là O(log n), nghĩa là thời gian tìm kiếm tăng rất chậm khi kích thước dữ liệu tăng lên. Điều này khác biệt đáng kể so với tìm kiếm tuyến tính, có độ phức tạp thời gian là O(n), trong đó thời gian tìm kiếm tăng tuyến tính với kích thước dữ liệu.
- Tốc độ: Tìm kiếm nhị phân nhanh hơn nhiều so với tìm kiếm tuyến tính, đặc biệt khi làm việc với danh sách lớn.
- Hiệu quả: Với độ phức tạp thời gian O(log n), tìm kiếm nhị phân rất hiệu quả trong việc tìm kiếm phần tử trong danh sách đã được sắp xếp.
- Ứng dụng rộng rãi: Thuật toán này được sử dụng trong nhiều lĩnh vực khác nhau của khoa học máy tính, bao gồm cơ sở dữ liệu, thuật toán nén dữ liệu và trí tuệ nhân tạo.
1.2 Hạn chế cần lưu ý của thuật toán tìm kiếm nhị phân
Mặc dù có nhiều ưu điểm, tìm kiếm nhị phân cũng có một số hạn chế cần lưu ý:
- Yêu cầu dữ liệu đã được sắp xếp: Tìm kiếm nhị phân chỉ hoạt động trên dữ liệu đã được sắp xếp. Nếu dữ liệu chưa được sắp xếp, bạn cần sắp xếp nó trước khi có thể sử dụng thuật toán này.
- Không hiệu quả với dữ liệu nhỏ: Với các danh sách rất nhỏ, sự khác biệt về hiệu suất giữa tìm kiếm nhị phân và tìm kiếm tuyến tính có thể không đáng kể. Trong một số trường hợp, tìm kiếm tuyến tính có thể nhanh hơn do không phải thực hiện các phép tính trung gian.
- Khó triển khai hơn tìm kiếm tuyến tính: Tìm kiếm nhị phân phức tạp hơn một chút so với tìm kiếm tuyến tính và có thể khó triển khai hơn, đặc biệt là đối với những người mới bắt đầu lập trình.
 Tìm kiếm nhị phân giúp tìm kiếm dữ liệu nhanh chóng
Tìm kiếm nhị phân giúp tìm kiếm dữ liệu nhanh chóng
2. Ứng Dụng Thực Tế Của Tìm Kiếm Nhị Phân Trong Đời Sống Và Công Việc
Tìm kiếm nhị phân không chỉ là một khái niệm lý thuyết trong sách giáo trình, mà còn là một công cụ mạnh mẽ được ứng dụng rộng rãi trong nhiều lĩnh vực của đời sống và công việc. Dưới đây là một số ví dụ điển hình:
2.1 Tìm kiếm thông tin trong danh bạ điện thoại
Khi bạn tìm kiếm một liên hệ trong danh bạ điện thoại của mình, điện thoại của bạn không tìm kiếm tuần tự từ đầu danh sách. Thay vào đó, nó sử dụng một biến thể của tìm kiếm nhị phân để nhanh chóng tìm ra tên bạn cần. Vì danh bạ được sắp xếp theo thứ tự bảng chữ cái, điện thoại có thể chia đôi danh sách liên tục cho đến khi tìm thấy tên hoặc xác định rằng nó không tồn tại.
2.2 Tìm kiếm từ trong từ điển
Tương tự như danh bạ điện thoại, từ điển được sắp xếp theo thứ tự bảng chữ cái. Khi bạn tra một từ, bạn không đọc từ đầu đến cuối từ điển. Thay vào đó, bạn mở từ điển ở một trang gần giữa, xem từ ở trang đó đứng trước hay sau từ bạn cần tìm, và tiếp tục chia đôi khoảng tìm kiếm cho đến khi tìm thấy từ đó.
2.3 Tìm kiếm sản phẩm trên các trang thương mại điện tử
Các trang thương mại điện tử lớn như Shopee, Lazada, Tiki có hàng triệu sản phẩm. Khi bạn tìm kiếm một sản phẩm cụ thể, hệ thống không thể tìm kiếm tuần tự qua tất cả các sản phẩm. Thay vào đó, nó sử dụng các thuật toán tìm kiếm phức tạp, trong đó tìm kiếm nhị phân đóng vai trò quan trọng trong việc thu hẹp phạm vi tìm kiếm và hiển thị kết quả nhanh chóng.
2.4 Tìm kiếm bản ghi trong cơ sở dữ liệu
Cơ sở dữ liệu là nơi lưu trữ lượng lớn thông tin có cấu trúc. Để tìm kiếm một bản ghi cụ thể trong cơ sở dữ liệu, các hệ quản trị cơ sở dữ liệu (DBMS) thường sử dụng các chỉ mục (index) được sắp xếp. Khi đó, tìm kiếm nhị phân có thể được sử dụng để tìm kiếm nhanh chóng các bản ghi trong chỉ mục, giúp tăng tốc độ truy vấn dữ liệu.
2.5 Xác định giá trị trung vị
Trong thống kê, giá trị trung vị là giá trị nằm giữa một tập dữ liệu đã được sắp xếp. Tìm kiếm nhị phân có thể được sử dụng để tìm giá trị trung vị một cách hiệu quả, đặc biệt là với các tập dữ liệu lớn. Theo Tổng cục Thống kê, việc xác định giá trị trung vị có vai trò quan trọng trong việc phân tích và đánh giá tình hình kinh tế – xã hội của một quốc gia.
3. Các Bước Triển Khai Thuật Toán Tìm Kiếm Nhị Phân
Để triển khai thuật toán tìm kiếm nhị phân, bạn có thể làm theo các bước sau:
3.1 Chuẩn bị dữ liệu
Đảm bảo rằng dữ liệu của bạn đã được sắp xếp theo thứ tự tăng dần hoặc giảm dần. Nếu dữ liệu chưa được sắp xếp, bạn cần sử dụng một thuật toán sắp xếp (ví dụ: sắp xếp nổi bọt, sắp xếp chèn, sắp xếp nhanh) để sắp xếp dữ liệu trước khi áp dụng tìm kiếm nhị phân.
3.2 Xác định điểm đầu, điểm cuối và điểm giữa
- Điểm đầu (L): Chỉ số của phần tử đầu tiên trong danh sách.
- Điểm cuối (R): Chỉ số của phần tử cuối cùng trong danh sách.
- Điểm giữa (M): (L + R) / 2 (làm tròn xuống nếu cần).
3.3 So sánh và thu hẹp phạm vi tìm kiếm
So sánh giá trị cần tìm (X) với giá trị của phần tử ở điểm giữa (A[M]):
- Nếu A[M] bằng X, bạn đã tìm thấy phần tử cần tìm.
- Nếu A[M] lớn hơn X, thu hẹp phạm vi tìm kiếm bằng cách đặt R = M – 1.
- Nếu A[M] nhỏ hơn X, thu hẹp phạm vi tìm kiếm bằng cách đặt L = M + 1.
3.4 Lặp lại quá trình
Lặp lại các bước 2 và 3 cho đến khi bạn tìm thấy phần tử cần tìm hoặc phạm vi tìm kiếm trở nên rỗng (L > R).
3.5 Xử lý trường hợp không tìm thấy
Nếu phạm vi tìm kiếm trở nên rỗng (L > R) mà bạn vẫn chưa tìm thấy phần tử cần tìm, điều đó có nghĩa là phần tử đó không có trong danh sách.
3.6 Ví dụ minh họa
Giả sử bạn có một mảng số đã được sắp xếp như sau: A = {2, 5, 7, 8, 11, 12}. Bạn muốn tìm số 13 trong mảng này.
- Khởi tạo: L = 0, R = 5
- Lặp 1: M = (0 + 5) / 2 = 2, A[2] = 7. Vì 7 < 13, nên L = 3.
- Lặp 2: M = (3 + 5) / 2 = 4, A[4] = 11. Vì 11 < 13, nên L = 5.
- Lặp 3: M = (5 + 5) / 2 = 5, A[5] = 12. Vì 12 < 13, nên L = 6.
- Kết thúc: Vì L > R (6 > 5), số 13 không có trong mảng.
 Minh họa các bước tìm kiếm nhị phân
Minh họa các bước tìm kiếm nhị phân
4. Mã Nguồn Ví Dụ Về Tìm Kiếm Nhị Phân
Dưới đây là mã nguồn ví dụ về thuật toán tìm kiếm nhị phân được viết bằng ngôn ngữ C++:
#include <iostream>
using namespace std;
bool binarySearch(int a[], int n, int x) {
// Khởi tạo left, right
int l = 0, r = n - 1;
while (l <= r) {
// Tính chỉ số của phần tử ở giữa
int m = (l + r) / 2;
if (a[m] == x) {
return true; // tìm thấy
} else if (a[m] < x) {
// tìm kiếm ở bên phải
l = m + 1;
} else {
// tìm kiếm ở bên trái
r = m - 1;
}
}
return false; // l > r
}
int main() {
int n = 12, x = 24, y = 6;
int a[12] = {1, 2, 3, 4, 5, 5, 7, 9, 13, 24, 27, 28};
if (binarySearch(a, n, x)) {
cout << "FOUNDn";
} else {
cout << "NOT FOUNDn";
}
if (binarySearch(a, n, y)) {
cout << "FOUNDn";
} else {
cout << "NOT FOUNDn";
}
return 0;
}Giải thích mã nguồn:
- Hàm
binarySearch(int a[], int n, int x)nhận vào một mảng số nguyêna, kích thước của mảngnvà giá trị cần tìmx. - Hàm sử dụng một vòng lặp
whileđể liên tục thu hẹp phạm vi tìm kiếm. - Trong mỗi lần lặp, hàm tính chỉ số của phần tử ở giữa (
m) và so sánh giá trị của phần tử đó với giá trị cần tìm (x). - Nếu tìm thấy phần tử cần tìm, hàm trả về
true. Nếu không tìm thấy, hàm trả vềfalse. - Hàm
main()tạo một mảng số nguyên và gọi hàmbinarySearch()để tìm kiếm hai giá trị khác nhau trong mảng.
Kết quả đầu ra:
FOUND
NOT FOUND Mã nguồn C++ minh họa thuật toán tìm kiếm nhị phân
Mã nguồn C++ minh họa thuật toán tìm kiếm nhị phân
5. Các Biến Thể Nâng Cao Của Thuật Toán Tìm Kiếm Nhị Phân
Ngoài phiên bản cơ bản, tìm kiếm nhị phân còn có nhiều biến thể nâng cao, được sử dụng để giải quyết các bài toán phức tạp hơn. Dưới đây là một số biến thể phổ biến:
5.1 Tìm vị trí đầu tiên của phần tử trong mảng đã sắp xếp tăng dần
Trong trường hợp mảng chứa nhiều phần tử có giá trị giống nhau, biến thể này giúp tìm vị trí xuất hiện đầu tiên của phần tử đó.
Mã nguồn ví dụ:
#include <iostream>
using namespace std;
int firstPos(int a[], int n, int x) {
int l = 0, r = n - 1;
int pos = -1; // cập nhật kết quả
while (l <= r) {
// Tính chỉ số của phần tử ở giữa
int m = (l + r) / 2;
if (a[m] == x) {
pos = m; // lưu lại
// Tìm thêm bên trái
r = m - 1;
} else if (a[m] < x) {
// tìm kiếm ở bên phải
l = m + 1;
} else {
// tìm kiếm ở bên trái
r = m - 1;
}
}
return pos;
}
int main() {
int n = 10, x = 3;
int a[10] = {1, 1, 2, 2, 3, 3, 3, 5, 7, 9};
int res = firstPos(a, n, x);
if (res == -1) {
cout << "3 khong xuat hien trong mangn";
} else {
cout << "Vi tri dau tien cua 3 trong mang : " << res << endl;
}
return 0;
}Kết quả đầu ra:
Vi tri dau tien cua 3 trong mang : 45.2 Tìm vị trí cuối cùng của phần tử trong mảng đã sắp xếp tăng dần
Tương tự như biến thể trên, biến thể này giúp tìm vị trí xuất hiện cuối cùng của phần tử trong mảng.
Mã nguồn ví dụ:
#include <iostream>
using namespace std;
int lastPos(int a[], int n, int x) {
int l = 0, r = n - 1;
int pos = -1; // cập nhật kết quả
while (l <= r) {
// Tính chỉ số của phần tử ở giữa
int m = (l + r) / 2;
if (a[m] == x) {
pos = m; // lưu lại
// Tìm thêm bên phải
l = m + 1;
} else if (a[m] < x) {
// tìm kiếm ở bên phải
l = m + 1;
} else {
// tìm kiếm ở bên trái
r = m - 1;
}
}
return pos;
}
int main() {
int n = 10, x = 3;
int a[10] = {1, 1, 2, 2, 3, 3, 3, 5, 7, 9};
int res = lastPos(a, n, x);
if (res == -1) {
cout << "3 khong xuat hien trong mangn";
} else {
cout << "Vi tri xuat hien cuoi cung cua 3 trong mang : " << res << endl;
}
return 0;
}Kết quả đầu ra:
Vi tri xuat hien cuoi cung cua 3 trong mang : 65.3 Tìm vị trí đầu tiên của phần tử lớn hơn hoặc bằng X trong mảng đã sắp xếp tăng dần
Biến thể này được sử dụng để tìm phần tử đầu tiên trong mảng có giá trị lớn hơn hoặc bằng một giá trị cho trước.
Mã nguồn ví dụ:
#include <iostream>
using namespace std;
int firstPos(int a[], int n, int x) {
int l = 0, r = n - 1;
int pos = -1; // cập nhật kết quả
while (l <= r) {
// Tính chỉ số của phần tử ở giữa
int m = (l + r) / 2;
if (a[m] >= x) {
pos = m; // lưu lại
// Tìm thêm bên trái
r = m - 1;
} else {
// tìm kiếm ở bên phải
l = m + 1;
}
}
return pos;
}
int main() {
int n = 10, x = 4;
int a[10] = {1, 1, 2, 2, 3, 3, 3, 5, 7, 9};
int res = firstPos(a, n, x);
if (res == -1) {
cout << "Khong ton tai so >= 4 trong mangn";
} else {
cout << "Vi tri cua phan tu dau tien >= 4 trong mang la : " << res << ", gia tri = " << a[res] << endl;
}
return 0;
}Kết quả đầu ra:
Vi tri cua phan tu dau tien >= 4 trong mang la : 7, gia tri = 5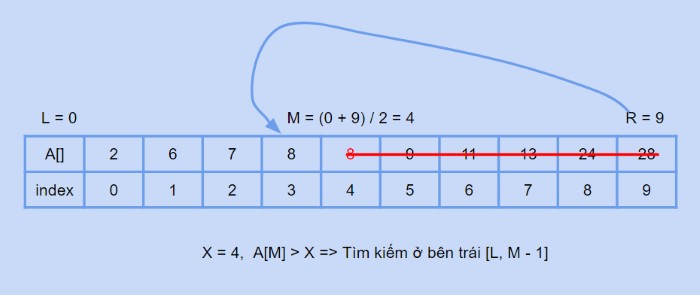 Mã nguồn C++ minh họa thuật toán tìm kiếm nhị phân nâng cao
Mã nguồn C++ minh họa thuật toán tìm kiếm nhị phân nâng cao
6. So Sánh Tìm Kiếm Nhị Phân Với Các Thuật Toán Tìm Kiếm Khác
Để hiểu rõ hơn về sức mạnh của tìm kiếm nhị phân, hãy so sánh nó với một số thuật toán tìm kiếm phổ biến khác:
| Thuật toán | Ưu điểm | Nhược điểm | Độ phức tạp thời gian (trung bình) |
|---|---|---|---|
| Tìm kiếm tuyến tính | Dễ triển khai, không yêu cầu dữ liệu đã được sắp xếp | Chậm với dữ liệu lớn | O(n) |
| Tìm kiếm nhị phân | Nhanh với dữ liệu lớn, độ phức tạp thời gian thấp | Yêu cầu dữ liệu đã được sắp xếp, khó triển khai hơn tìm kiếm tuyến tính | O(log n) |
| Tìm kiếm nội suy | Có thể nhanh hơn tìm kiếm nhị phân nếu dữ liệu được phân phối đều | Hiệu suất kém nếu dữ liệu không được phân phối đều, phức tạp hơn tìm kiếm nhị phân | O(log log n) |
| Bảng băm (Hash table) | Thời gian tìm kiếm trung bình là O(1) | Yêu cầu thêm không gian lưu trữ, có thể xảy ra xung đột (collision), độ phức tạp thời gian trong trường hợp xấu nhất là O(n) | O(1) |
Từ bảng so sánh trên, có thể thấy rằng tìm kiếm nhị phân là một lựa chọn tốt khi bạn cần tìm kiếm dữ liệu trong một danh sách lớn đã được sắp xếp. Tuy nhiên, nếu dữ liệu của bạn không được sắp xếp hoặc bạn cần thực hiện tìm kiếm rất thường xuyên, các thuật toán khác như bảng băm có thể phù hợp hơn.
7. Các Câu Hỏi Thường Gặp Về Tìm Kiếm Nhị Phân (FAQ)
Dưới đây là một số câu hỏi thường gặp về thuật toán tìm kiếm nhị phân:
7.1 Tìm kiếm nhị phân có thể được sử dụng trên dữ liệu không được sắp xếp không?
Không, tìm kiếm nhị phân chỉ hoạt động trên dữ liệu đã được sắp xếp. Nếu bạn cố gắng sử dụng nó trên dữ liệu không được sắp xếp, kết quả sẽ không chính xác.
7.2 Độ phức tạp thời gian của tìm kiếm nhị phân là gì?
Độ phức tạp thời gian của tìm kiếm nhị phân là O(log n), trong đó n là kích thước của dữ liệu. Điều này có nghĩa là thời gian tìm kiếm tăng rất chậm khi kích thước dữ liệu tăng lên.
7.3 Tìm kiếm nhị phân có nhanh hơn tìm kiếm tuyến tính không?
Có, tìm kiếm nhị phân nhanh hơn nhiều so với tìm kiếm tuyến tính, đặc biệt khi làm việc với dữ liệu lớn.
7.4 Khi nào nên sử dụng tìm kiếm nhị phân?
Bạn nên sử dụng tìm kiếm nhị phân khi bạn cần tìm kiếm dữ liệu trong một danh sách lớn đã được sắp xếp.
7.5 Có những biến thể nào của tìm kiếm nhị phân?
Có nhiều biến thể của tìm kiếm nhị phân, bao gồm tìm vị trí đầu tiên, tìm vị trí cuối cùng và tìm phần tử lớn hơn hoặc bằng một giá trị cho trước.
7.6 Làm thế nào để triển khai tìm kiếm nhị phân?
Bạn có thể triển khai tìm kiếm nhị phân bằng cách sử dụng một vòng lặp while để liên tục thu hẹp phạm vi tìm kiếm.
7.7 Tìm kiếm nhị phân có thể được sử dụng để tìm kiếm chuỗi không?
Có, tìm kiếm nhị phân có thể được sử dụng để tìm kiếm chuỗi trong một danh sách các chuỗi đã được sắp xếp theo thứ tự bảng chữ cái.
7.8 Tìm kiếm nhị phân có thể được sử dụng để tìm kiếm trong cây nhị phân tìm kiếm (BST) không?
Có, tìm kiếm nhị phân có thể được sử dụng để tìm kiếm trong cây nhị phân tìm kiếm.
7.9 Tìm kiếm nhị phân có phải là thuật toán tìm kiếm tốt nhất trong mọi trường hợp không?
Không, tìm kiếm nhị phân không phải là thuật toán tìm kiếm tốt nhất trong mọi trường hợp. Nếu dữ liệu của bạn không được sắp xếp hoặc bạn cần thực hiện tìm kiếm rất thường xuyên, các thuật toán khác như bảng băm có thể phù hợp hơn.
7.10 Làm thế nào để tối ưu hóa tìm kiếm nhị phân?
Một cách để tối ưu hóa tìm kiếm nhị phân là sử dụng tìm kiếm nội suy thay vì tính chỉ số giữa bằng cách chia đôi khoảng tìm kiếm. Tuy nhiên, tìm kiếm nội suy chỉ hiệu quả khi dữ liệu được phân phối đều.
8. Liên Hệ Với Xe Tải Mỹ Đình Để Được Tư Vấn Chuyên Sâu Về Xe Tải
Bạn đang tìm kiếm thông tin chi tiết và đáng tin cậy về xe tải ở Mỹ Đình? Bạn muốn được tư vấn lựa chọn xe tải phù hợp với nhu cầu và ngân sách của mình? Hãy đến với XETAIMYDINH.EDU.VN ngay hôm nay!
Tại Xe Tải Mỹ Đình, chúng tôi cung cấp:
- Thông tin chi tiết và cập nhật về các loại xe tải có sẵn ở Mỹ Đình, Hà Nội.
- So sánh giá cả và thông số kỹ thuật giữa các dòng xe.
- Tư vấn lựa chọn xe phù hợp với nhu cầu và ngân sách của bạn.
- Giải đáp các thắc mắc liên quan đến thủ tục mua bán, đăng ký và bảo dưỡng xe tải.
- Thông tin về các dịch vụ sửa chữa xe tải uy tín trong khu vực.
Đừng ngần ngại liên hệ với chúng tôi theo thông tin sau để được tư vấn và giải đáp mọi thắc mắc:
- Địa chỉ: Số 18 đường Mỹ Đình, phường Mỹ Đình 2, quận Nam Từ Liêm, Hà Nội
- Hotline: 0247 309 9988
- Trang web: XETAIMYDINH.EDU.VN
Chúng tôi luôn sẵn lòng hỗ trợ bạn tìm được chiếc xe tải ưng ý nhất!