Vector hóa dữ liệu là một kỹ thuật quan trọng trong deep learning, giúp tăng tốc độ tính toán và hiệu quả huấn luyện mô hình. Bài viết này sẽ tập trung vào “vector xe tải trừu tượng” như một ví dụ minh họa cho việc áp dụng vector hóa, đồng thời thảo luận về các kỹ thuật tối ưu hóa khác như mini-batch gradient descent, xử lý bias-variance và dropout.
Vector hóa trong Deep Learning: Ví dụ về Vector Xe Tải Trừu Tượng
Vector hóa (vectorization) là quá trình chuyển đổi dữ liệu thành dạng vector hoặc ma trận, cho phép thực hiện các phép tính toán song song trên CPU hoặc GPU. Thay vì xử lý từng phần tử dữ liệu riêng lẻ bằng vòng lặp, vector hóa cho phép xử lý đồng thời nhiều phần tử, từ đó giảm đáng kể thời gian tính toán.
Hãy tưởng tượng “vector xe tải trừu tượng” là một vector biểu diễn các đặc trưng của một chiếc xe tải, chẳng hạn như trọng tải, kích thước, loại hàng vận chuyển. Mỗi đặc trưng này sẽ là một phần tử trong vector. Việc sử dụng vector cho phép chúng ta thực hiện các phép tính toán trên toàn bộ tập hợp đặc trưng cùng một lúc, thay vì tính toán từng đặc trưng một. Ví dụ, nếu muốn tính tổng trọng tải của 10 chiếc xe tải, ta có thể thực hiện phép cộng vector một lần duy nhất, thay vì dùng vòng lặp để cộng trọng tải của từng xe.
Việc áp dụng vector hóa trong bài toán dự đoán giá xe tải cũ dựa trên các đặc trưng của nó sẽ mang lại hiệu quả tính toán cao hơn so với việc sử dụng vòng lặp. Các thư viện như NumPy hỗ trợ mạnh mẽ vector hóa, giúp việc triển khai các thuật toán deep learning trở nên hiệu quả hơn.
 Vector xe tải trừu tượng
Vector xe tải trừu tượng
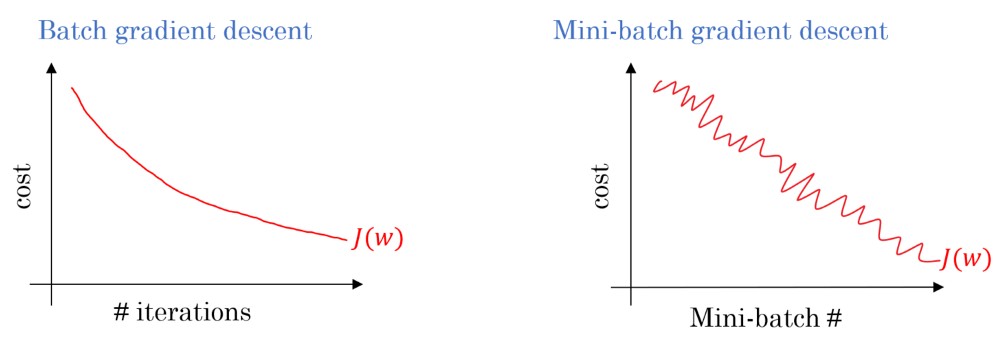
Mini-Batch Gradient Descent: Tối Ưu Huấn Luyện Mô Hình
Khi huấn luyện mô hình deep learning với lượng dữ liệu lớn, việc sử dụng toàn bộ dữ liệu để tính toán gradient trong mỗi bước lặp (batch gradient descent) sẽ rất tốn kém về thời gian và tài nguyên. Mini-batch gradient descent là một giải pháp hiệu quả, chia dữ liệu thành các batch nhỏ hơn và tính toán gradient trên từng batch.
Trong trường hợp “vector xe tải trừu tượng”, mini-batch gradient descent sẽ chia tập dữ liệu xe tải thành các nhóm nhỏ. Mỗi nhóm sẽ được sử dụng để cập nhật trọng số của mô hình. Việc này giúp tăng tốc quá trình huấn luyện và giảm thiểu việc sử dụng bộ nhớ.
Xử Lý Bias và Variance: Cân bằng Mô Hình
Bias và variance là hai yếu tố quan trọng ảnh hưởng đến hiệu suất của mô hình. High bias (underfitting) xảy ra khi mô hình quá đơn giản và không thể học được các đặc trưng phức tạp của dữ liệu. High variance (overfitting) xảy ra khi mô hình quá phức tạp và học thuộc lòng dữ liệu huấn luyện, dẫn đến khả năng tổng quát hóa kém.
Để cân bằng mô hình, ta cần tìm điểm giao thoa giữa bias và variance. Các kỹ thuật như regularization (L1, L2) và dropout có thể giúp giảm overfitting.
Dropout: Ngăn Ngừa Overfitting
Dropout là một kỹ thuật regularization, ngẫu nhiên “tắt” một số neuron trong quá trình huấn luyện. Điều này giúp ngăn ngừa việc mô hình quá phụ thuộc vào một số neuron cụ thể, từ đó tăng khả năng tổng quát hóa.
Activation Function: Vai trò của Phi Tuyến Tính
Hàm activation (hàm kích hoạt) đóng vai trò quan trọng trong việc đưa phi tuyến tính vào mô hình. Các hàm activation phổ biến bao gồm sigmoid, tanh, ReLU và Leaky ReLU. Việc lựa chọn hàm activation phù hợp có thể ảnh hưởng đến tốc độ huấn luyện và hiệu suất của mô hình. ReLU và các biến thể của nó thường được ưa chuộng do tính toán đơn giản và khả năng khắc phục vanishing gradient.
Kết Luận
Vector hóa, mini-batch gradient descent, xử lý bias-variance, dropout và activation function là những kỹ thuật quan trọng giúp tối ưu hiệu suất của mô hình deep learning. Việc áp dụng các kỹ thuật này một cách hợp lý sẽ giúp xây dựng được mô hình mạnh mẽ và có khả năng tổng quát hóa cao. “Vector xe tải trừu tượng” là một ví dụ minh họa cho thấy sức mạnh của vector hóa trong việc xử lý dữ liệu và huấn luyện mô hình. Liên hệ Xe Tải Mỹ Đình để tìm hiểu thêm về ứng dụng của công nghệ trong lĩnh vực vận tải.
